Learn about the main characteristics of the different algorithm training types.
You need to be familiar with the different algorithm training types to be able to choose the most suitable one for your training. To help you achieve this we prepared this section for you.
What to expect from this page?
| Table of Contents | ||||||
|---|---|---|---|---|---|---|
|
📑 Semantic segmentation
If you need to know which label each pixel of the image belongs to, or need to find areas or boundaries of objects, semantic segmentation is the best training type for you.
By using semantic segmentation, the exact areas, locations, and boundaries of an object or a group of objects can be determined. It allows you to find out which regions of the image belong to which label. The result is a pixel-wise map of the original image corresponding to the output labels.
Semantic segmentation is one of the main tasks performed in autonomous driving, e.g. the car needs to be aware of where the road is and where its exact boundaries to other objects are. In medical applications, semantic segmentation is used to, e.g. find the boundaries of organs in CT scans and reconstruct the 3D structure of the observed organ.
.png?version=2&modificationDate=1656326552373&cacheVersion=1&api=v2&width=510)

📑 Image classification
If you need to know what the picture shows, image classification might be the best training algorithm type for you.
Image classification algorithms identify WHAT is seen in a given image. This method is used for assigning the whole input image to a class based on the objects shown in the image. Image classification is the most widely used task for deep learning models.
Algorithms trained for image classification are able to assign a certain class to the image based on what is shown in the image. This way the model is able to distinguish e.g. a picture of a cat from a picture of a dog. Further, it can also discriminate between different dog breeds or even pictures of completely unrelated objects or persons. Models trained on individual datasets from the popular database ImageNet, for example, are able to distinguish between more than 20,000 categories.

The output of a typical image classification model is a list of probabilities for categories that the image might contain. The category with the highest probability corresponds to what the model “thinks“ the image represents.
📑 Object detection
If you need to know what is on your image and where it is located in your image, object detection might be the most suitable training type for your use case.
Object detection checks if a certain object is present in the image - and if so - where it is located. Although this training type may appear similar to the previous ones, there are some significant differences.
While segmentation algorithms actually label objects and yield the exact object outline, analysis is relatively slow and the resulting data set is more complex. Segmentation may also be limited when different instances of the same object overlap.
Object detection algorithms are significantly faster. Annotation is less complex, as the output data includes the coordinates of a rectangular ‚bounding box’ around the object instead of exact boundaries. In addition, object detection algorithms are better at separating different instances of the same object when they are nearby or overlapping.
This algorithm type is thus useful for analyzing large whole slide images, where you are e.g., interested in the counting objects. Object detection algorithms are widely used for identifying objects in images and separating them for further analysis. For instance, this is a standard technique for recognizing faces in digital camera applications — or even smiling faces in views.

📑 Instance segmentation
Combining object detection and semantic segmentation capabilities, instance segmentation is one of the more versatile training types. Just like semantic segmentation, an instance segmentation algorithm training yields a pixel-wise map assigning each pixel in the image to one of the detected labels. At the same time it provides a bounding box location for all individual instances of this object class shown in the image.

Figure 4 features two ladybugs. If this image was to be analyzed with semantic segmentation only, one could easily differentiate between pixels containing ladybugs, leaves or the background (as can be seen in Figure 5).


However, semantic segmentation will not allow to easily differentiate between the positions of the two depicted ladybugs. As the two are touching, there is no straightforward way to know even that there are two ladybugs in this picture based on semantic segmentation alone.
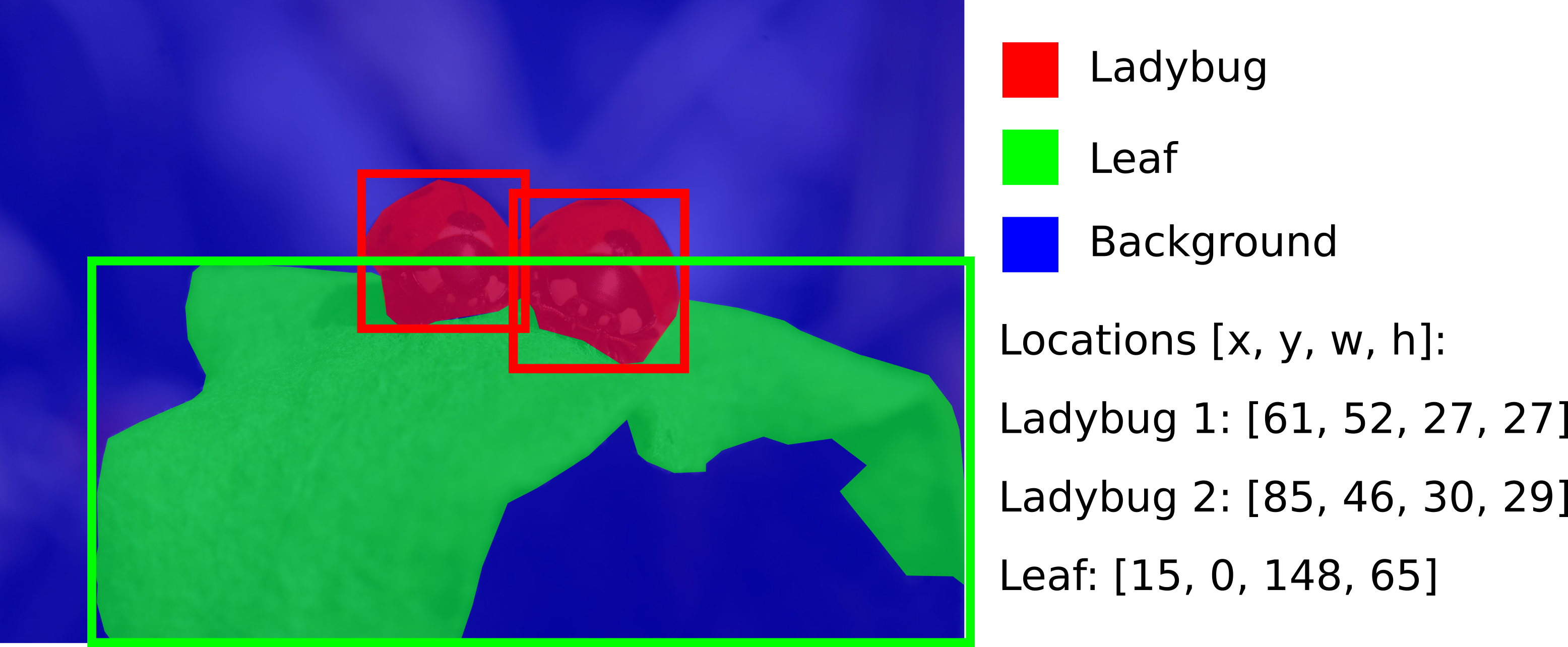
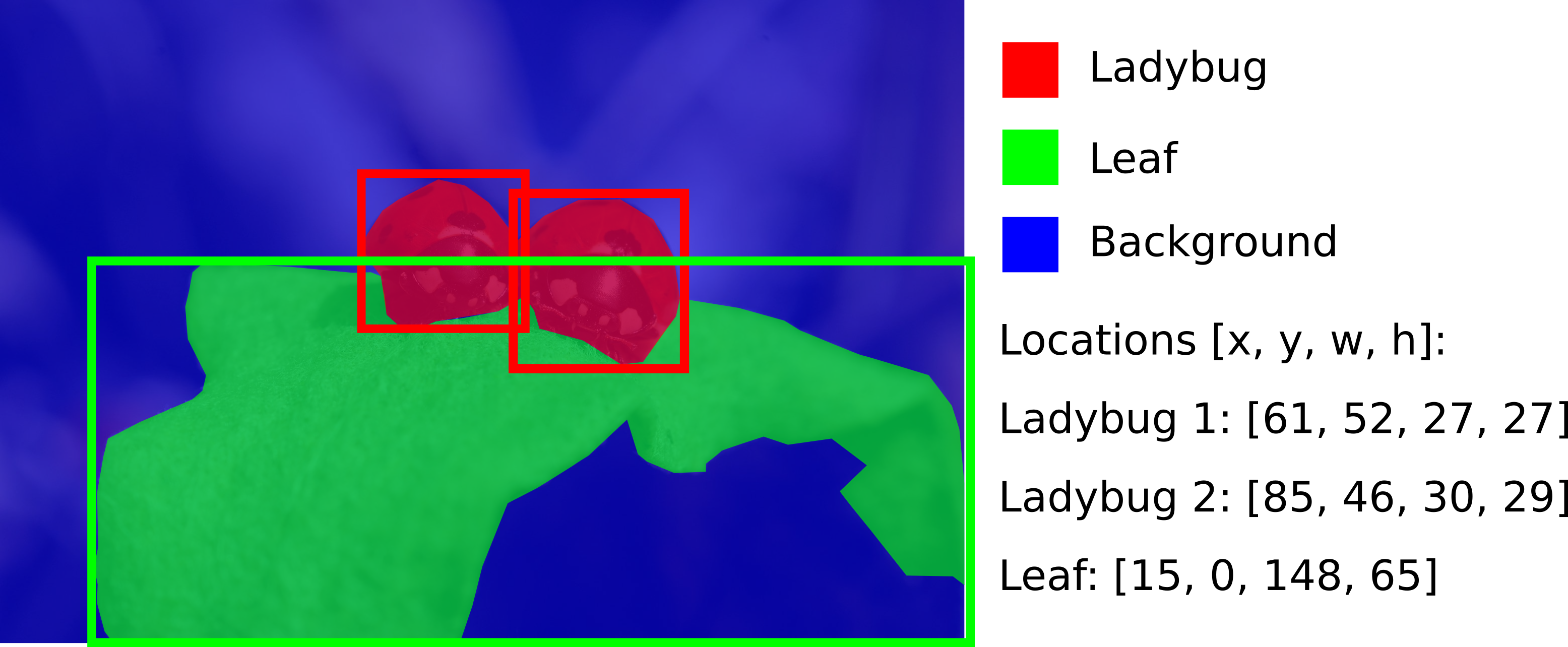
Instance segmentation extends the functionality of semantic segmentation by adding object detection to the analysis. In addition to yielding a segmentation map, an instance segmentation algorithm will also provide information on the locations and sizes of the bounding boxes of each object instance depicted in the image.
This allows for further analysis on the instance-level such as counting instances, measuring distances between instances or examining the area covered with (or even surrounding the) instances.
Now you know everything about the various algorithm training types.
Share this information with your team members/colleagues and discuss which one is the most suitable training type for your purposes. Enjoy your algorithm training.
If you still have questions regarding your algorithm training, feel free to send us an email at support@ikosa.ai. Copy-paste your training ID in the subject line of your email.
📚 Related articles
| Filter by label | ||||||||
|---|---|---|---|---|---|---|---|---|
|